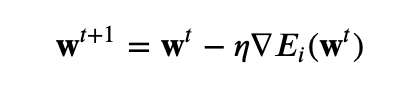Hello,
I just wanted to point out a small notation discrepancy in the last part of point 1.2 :
The algorithm given for updating the w^t+1 is the one for gradient descent as (per the current notation) it uses the gradient of entire loss function, whereas it should be the gradient of the loss function for a single sample n (per the definition of SGD). This also apply to the instruction of deriving the gradient of the loss function in order to apply the update on the weights. Nothing too big, but writing a gradient descent version for the perceptron problem results in a different implementation as the one suggested by the snipped below.
Best regards,
Tim.