1) Reading your vhdl code, when you start to write in memory, do NOT wait until avm_WaitRequest is = '0' to put avm_Add, BE, Wr and WrData
Just wait to finish the transfer to verify that avm_WaitRequest is at '0'
Depending on the avalon implementation wait_request is allowed to be directly activated when a cycle start.
2) Another way, and more universal when a processor and a DMA have to work together is to use the FLUSH type instructions
https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/hb/nios2/edh_ed51002.pdf
"Your application can share non-cache-bypassed memory regions with external
masters if it runs the alt_dcache_flush() function before it allows the external
master to operate on the memory"
"The alt_dcache_flush_all() function call flushes the entire data cache, but this
function is not efficient. Altera recommends that you flush from the cache only the
entries for the memory region that you make available to the other master peripheral"
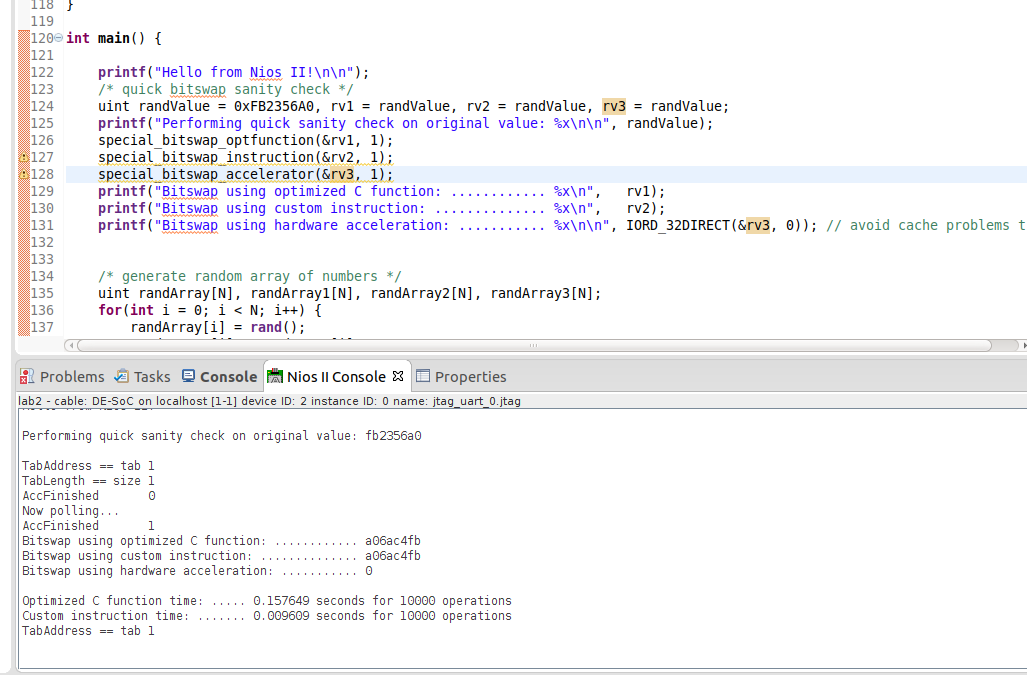
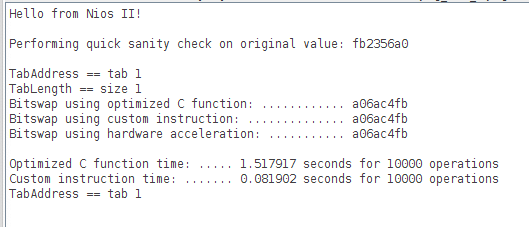
3) Use the IORD_xxDIRECT(base, offset), IOWR_xxDIRECT(base, offset, data) macro from "io.h", offset address in number of byte from a base address, and size of transfers depending on the xx: 8, 16, 32 bits.
IORD() and IOWR() are doing 32 bits access only ond the offset is provide as 32 bits size transfers and not byte. More for programmable interface access than memory. The main characteristic of those macro is to use assembly level uncacheable memory space access.
Another way, but deprecated is to put address bit 31 @'1' when doing an access by the processor with normal instructions, but no more recommended.
Best.
RB
| #define __IO_CALC_ADDRESS_DYNAMIC(BASE, OFFSET) \ |
| ((void *)(((alt_u8*)BASE) + (OFFSET))) |
|
|
| #define IORD_32DIRECT(BASE, OFFSET) \ |
| __builtin_ldwio (__IO_CALC_ADDRESS_DYNAMIC ((BASE), (OFFSET))) |
| #define IORD_16DIRECT(BASE, OFFSET) \ |
| __builtin_ldhuio (__IO_CALC_ADDRESS_DYNAMIC ((BASE), (OFFSET))) |
| #define IORD_8DIRECT(BASE, OFFSET) \ |
| __builtin_ldbuio (__IO_CALC_ADDRESS_DYNAMIC ((BASE), (OFFSET))) |
|
|
| #define IOWR_32DIRECT(BASE, OFFSET, DATA) \ |
| __builtin_stwio (__IO_CALC_ADDRESS_DYNAMIC ((BASE), (OFFSET)), (DATA)) |
| #define IOWR_16DIRECT(BASE, OFFSET, DATA) \ |
| __builtin_sthio (__IO_CALC_ADDRESS_DYNAMIC ((BASE), (OFFSET)), (DATA)) |
| #define IOWR_8DIRECT(BASE, OFFSET, DATA) \ |
| __builtin_stbio (__IO_CALC_ADDRESS_DYNAMIC ((BASE), (OFFSET)), (DATA)) |
|
|
| /* Native bus access functions */ |
|
|
| #define __IO_CALC_ADDRESS_NATIVE(BASE, REGNUM) \ |
| ((void *)(((alt_u8*)BASE) + ((REGNUM) * (SYSTEM_BUS_WIDTH/8)))) |
|
|
| #define IORD(BASE, REGNUM) \ |
| __builtin_ldwio (__IO_CALC_ADDRESS_NATIVE ((BASE), (REGNUM))) |
| #define IOWR(BASE, REGNUM, DATA) \ |
| __builtin_stwio (__IO_CALC_ADDRESS_NATIVE ((BASE), (REGNUM)), (DATA)) |
|