Hello,
I have some troubles with the exam of 2020 :

Fot this question we are asked to use logistic regression to solve the problem. As logistic regression is a binary classification problem we can only output a 1 or -1 for example. So for me it is not possible to predict the salary or a disease. For the third option we have an image and the annotations images and given a new image we wan't to predict the routes. Here we have in fact a classification but in much more than 2 groups so logistic regression will not be able to separate the data with a simple line.
So for me the only right answer is the last one. We have features and we have to predict if the students pass (1) or not (-1).
The problem is that only answer 2 and 3 are right and I'm realy confused about that. It would be great if someone can explain me why I'm wrong !
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
I have another question concerning the feature expansion. If we do a polynomial feature expansion of degree 2 for a vector [x1, x2]
we have [x1, x2, x1^2, x2^2, x1x2]. I'm not sure how this formula is defined. Do we have to include the simple terms ? Do the mixed terms have to be multiplied by 2 ? Is there a formula in the course that I forgot ?
And now if we compare a polynomial feature expansion with a polynomial kernel we have to find the same expression :
so the polynomial kernel is defined as 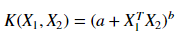
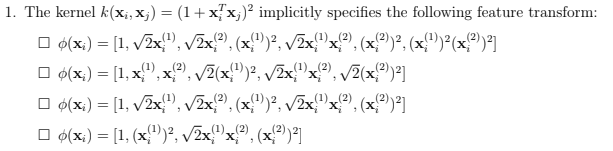
And here in the question we have to find k(xi, xj) = phi(xi)phi(xj)^T. The right answer is the 3rd one. If we do the calculations we find this expansion. But for me this is absolutely not of the polynomial form which should look like :
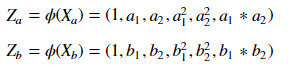
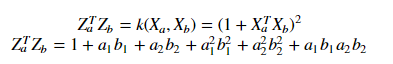
So I'm pretty confused and I was wondering if I'm doing something completely wrong ?
Thank's in advance for your help !