Hi,
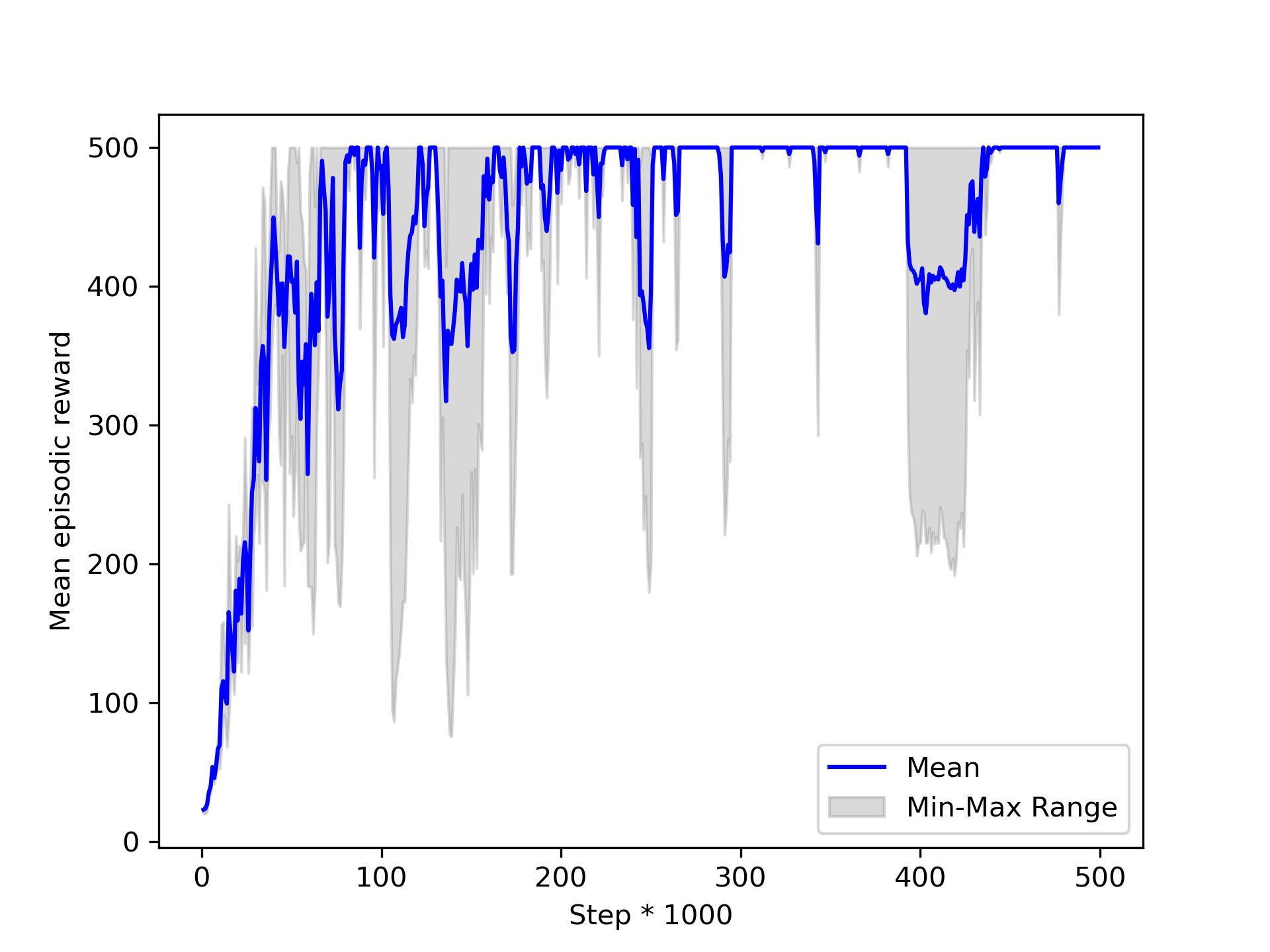
On Tuesday you told us we should be careful when using parallel envs from gymnasium, in particular at truncation where we should retrieve the truncated state to compute the loss. We implemented this and what we get for the agent 0 seems a bit better (even if it still seems quite unstable depending on the seed).
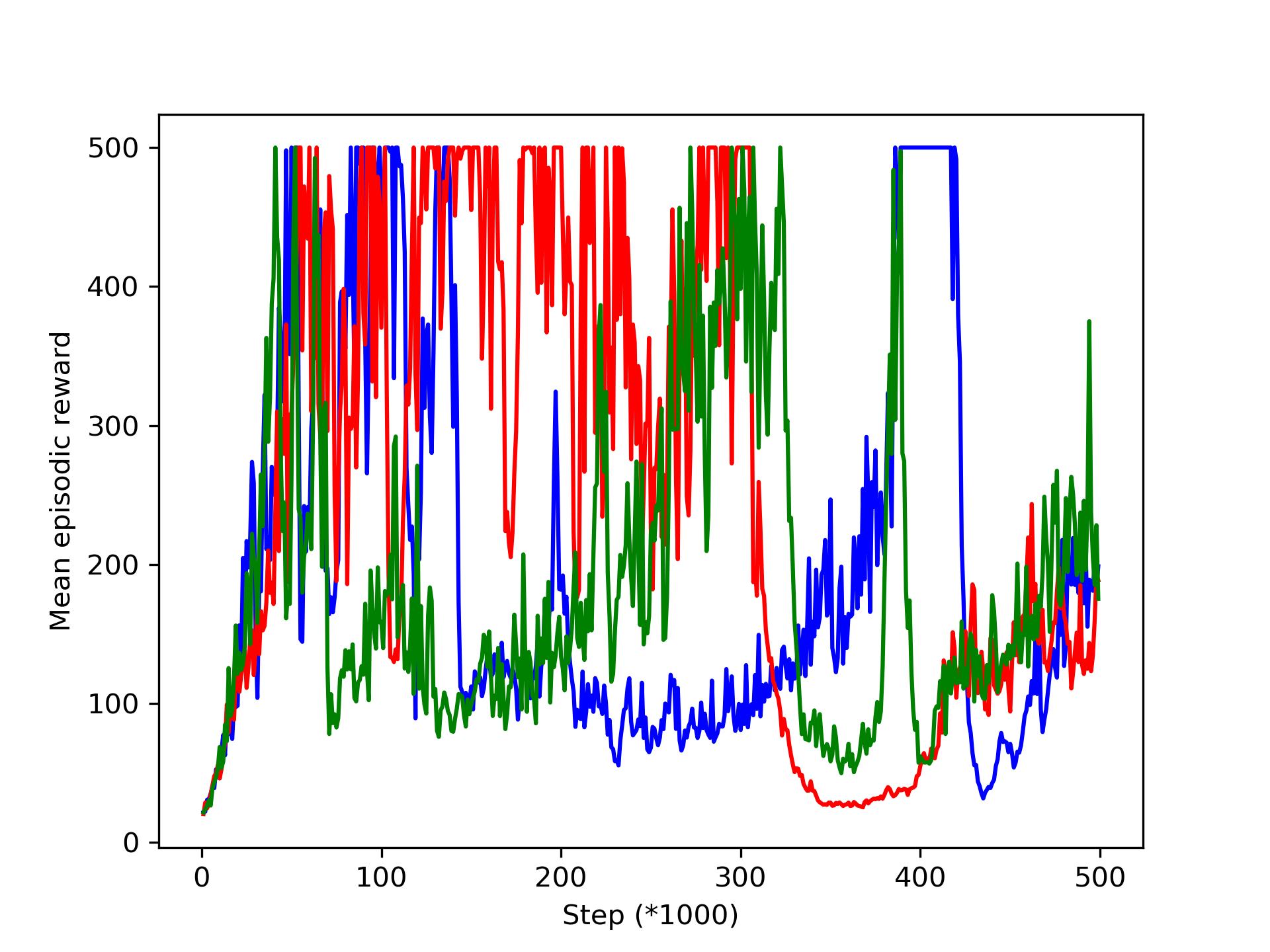
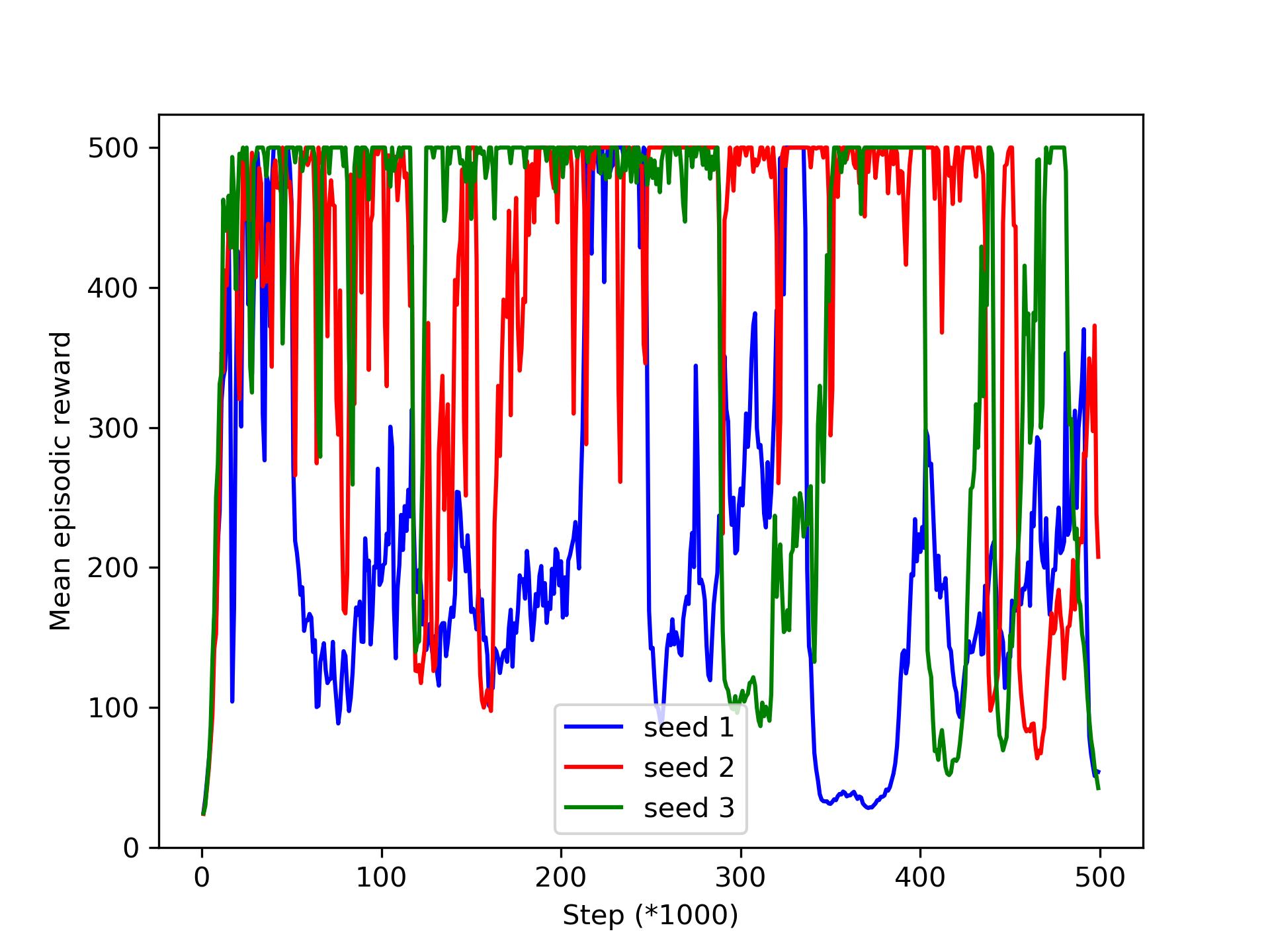
But when we get to sparse rewards, it really doesn't seem to reach the optimal policy : it does go up to 500 but it's terribly unstable. Is it normal ? Since the rewards are very sparse I would say yes but since you say we should reach the optimal policy I'm not so sure what you mean, also I don't think it corresponds to what you showed us. Same thing when we go to 6 workers : it get better than with only 1 but it still seem quite unstable, we don't know if it's normal or not.
Moreover, it seems like each time the mean episodic reward goes up to 500 very fast (in like 10-15k steps) which doesn't make sense to us.
- To compute the mean episodic reward we add at each new step the reward (so 1) to a variable and each time there is termination or a truncation, we put this value into a list, put the variable back to 0 and go on. Then every 1000 steps, we take the mean of the list (when we have k workers we have k of these lists so k values and we take the average of the k values), this is what we call the mean episodic reward and the values we plot. Is that a correct approach ?
- For the sparse rewards, we give a reward of 0 90% of the time to the learner to compute the loss, but not to the logging, did we understand it well ?
Are we missing something ? Would you have any other hint on where the problem could come from ? We are really lost and we don't understand what are we doing wrong here.
Thanks in advance.
The order of the plots are first agent 0 then agent 1 then agent 2.