Hello, for the auixilary reward I am adding the following rewards:
- State dependent - I reward if the agent is moving towards the top. It is between 0 and 1, where 0 is in the middle or on the left side, and 1 is on the top
- Velocity dependent - I am rewarding a positive velocity, and it is also between 0 and 1
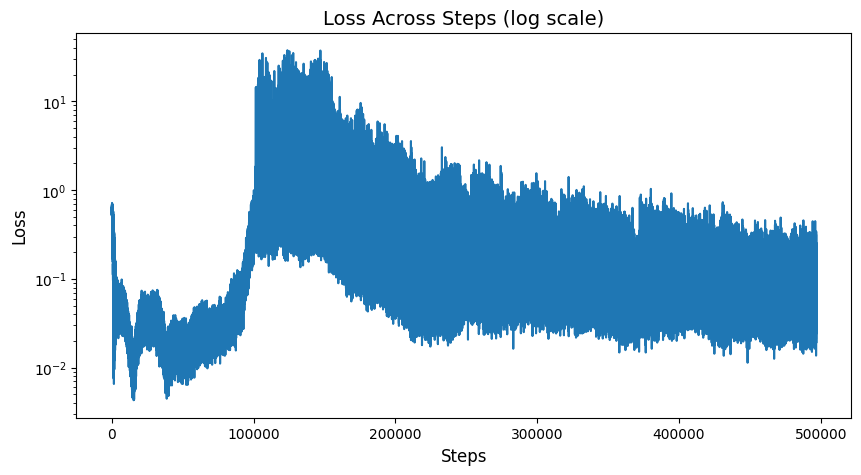
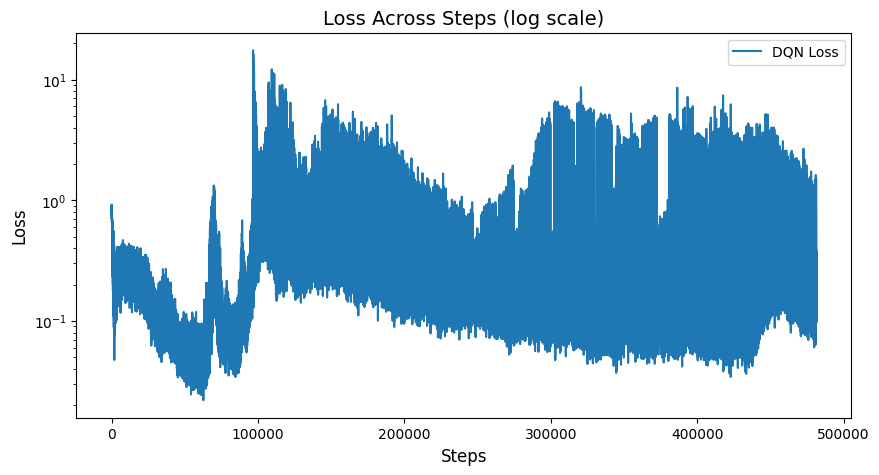
When I train the agent, the loss keeps decreasing when the agent gets truncated without reaching the top, but once it starts reaching the destination more frequently the loss starts increasing and ends up diverging basically.
This is the lenght of episodes
and this is the loss:
Here it is given for ~1500 episodes, but it goes the same way until 3000 episodes.
What do you think could be the reason? What do you recommend?