Hello,
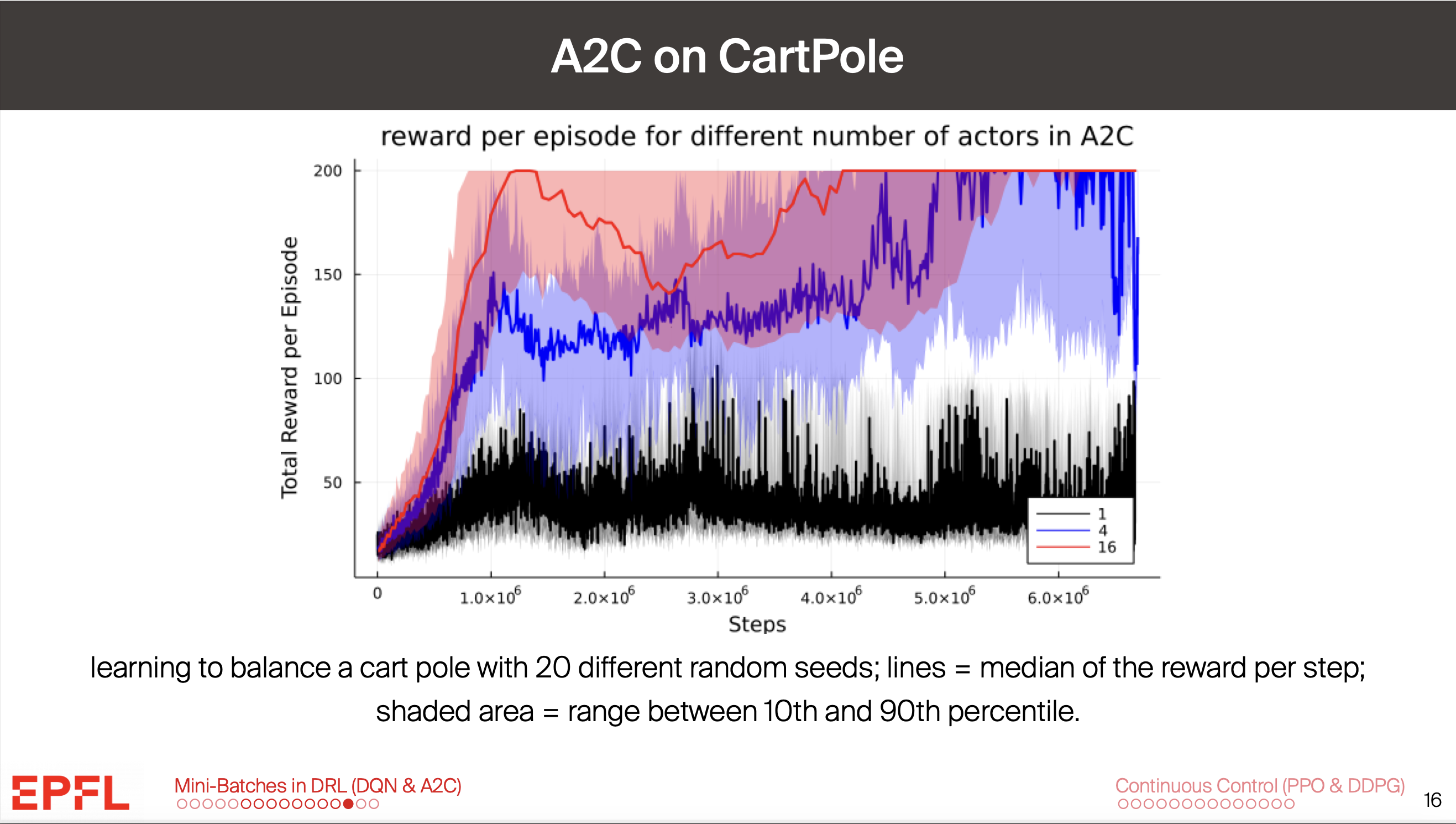
During our lecture on Deep RL, slide 16 shows that A2C with 1 worker (on a cartpole task) doesn't converge to an optimal policy even within 6 million steps. Meanwhile, the project pdf (for the A2C on cartpole problem) states that for 1 worker and no batches, our agent should reach the optimal policy within 500k steps:
"Success criteria and questions. Your agent should reach an optimal policy (i.e. an episodic return of 500) with most of your random seeds."
I am confused as to what to expect regarding my own results (my agent does not converge). Which source is right in this case?
Best,
Alexei Ermochkine
the lecture slide in question: