Hello,
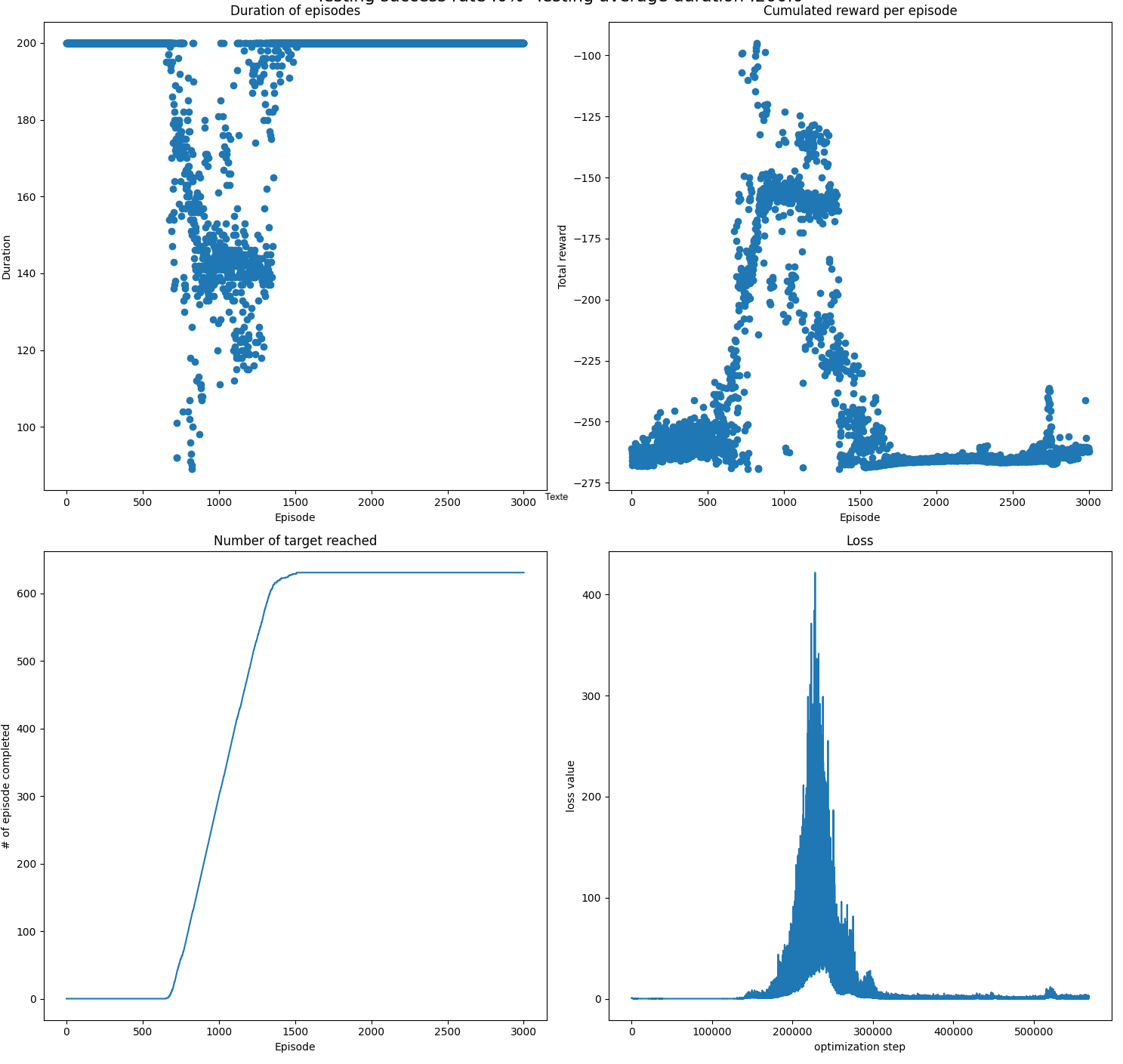
For the part 3.3, with the heuristic function I added, an optimal policy is found at after around 1000 training episode, then the loss start increasing (as mentioned here), and finally, the agent forget the optimal policy as the loss is going back to small values. My heuristic reward is always smaller than 0. So basically if we stop to 1000 training episode, we have a fully successful policy, but if we keep training to 3000, we dont reach the target anymore. Is there a way to fix that (maybe with a better heuristic reward) or can we afford to stop when a good policy is found ?
Here's some graph of the situation :