Dear TAs,
I have a question regarding making steps in policy gradient in Deep RL. In slide 25, week 8 (see screenshot below), why do we consider the samples from policy and probability with weights theta prime and not theta? What would be the difference between J(theta) in slide 24 and slide 25?
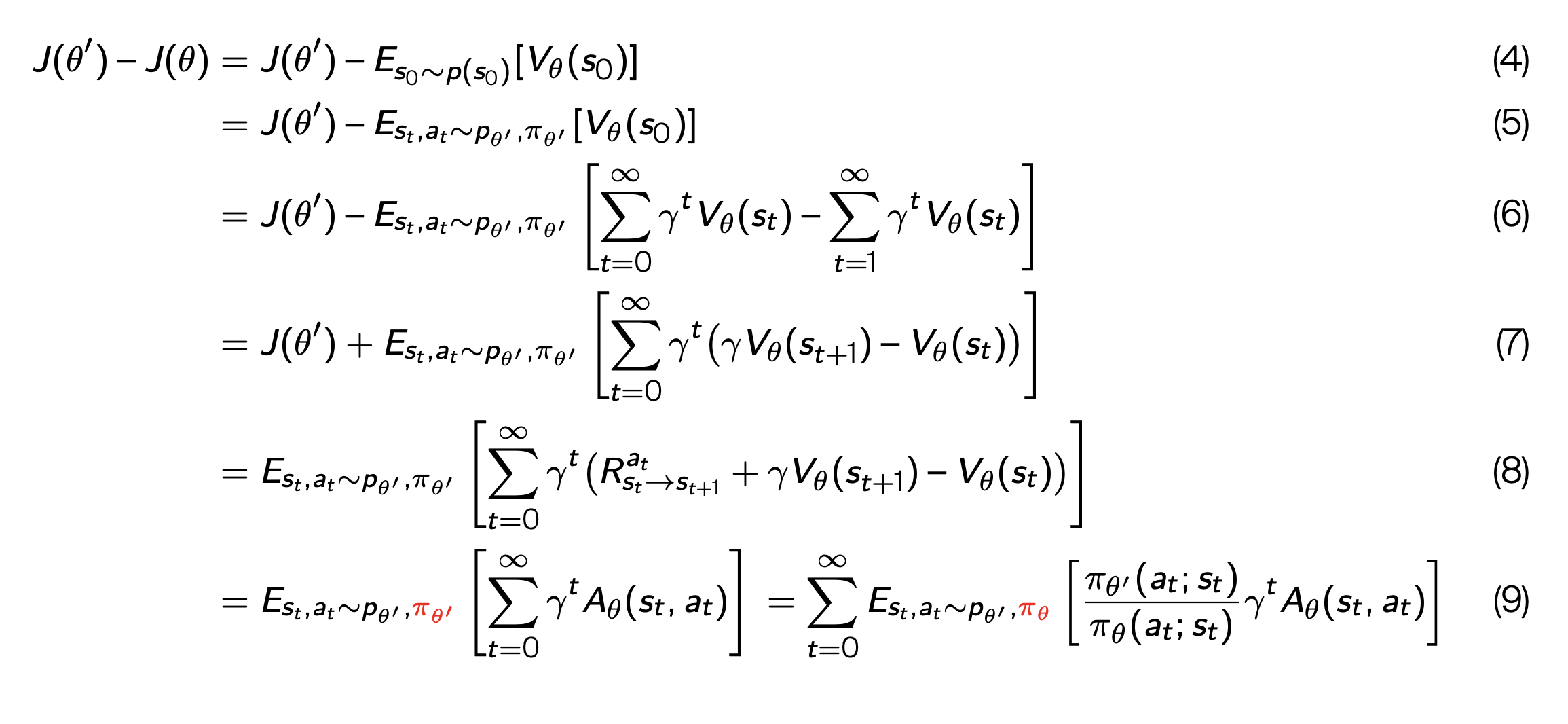
Thank you in advance!
Best wishes,
Maria