Hello,
We have implemented the Question 3.a for the DQN project, trained the network for 500 episodes with parameters given in the .pdf : We use a 3 hidden layer fully connected neural net with layers of size input size, 64, 32, 16, output size, the learning rate is 5 · 10−3, the discount factor is 0.9, the batch size is 2048 and the buffer size is 20000. The epsilon is 0.7.
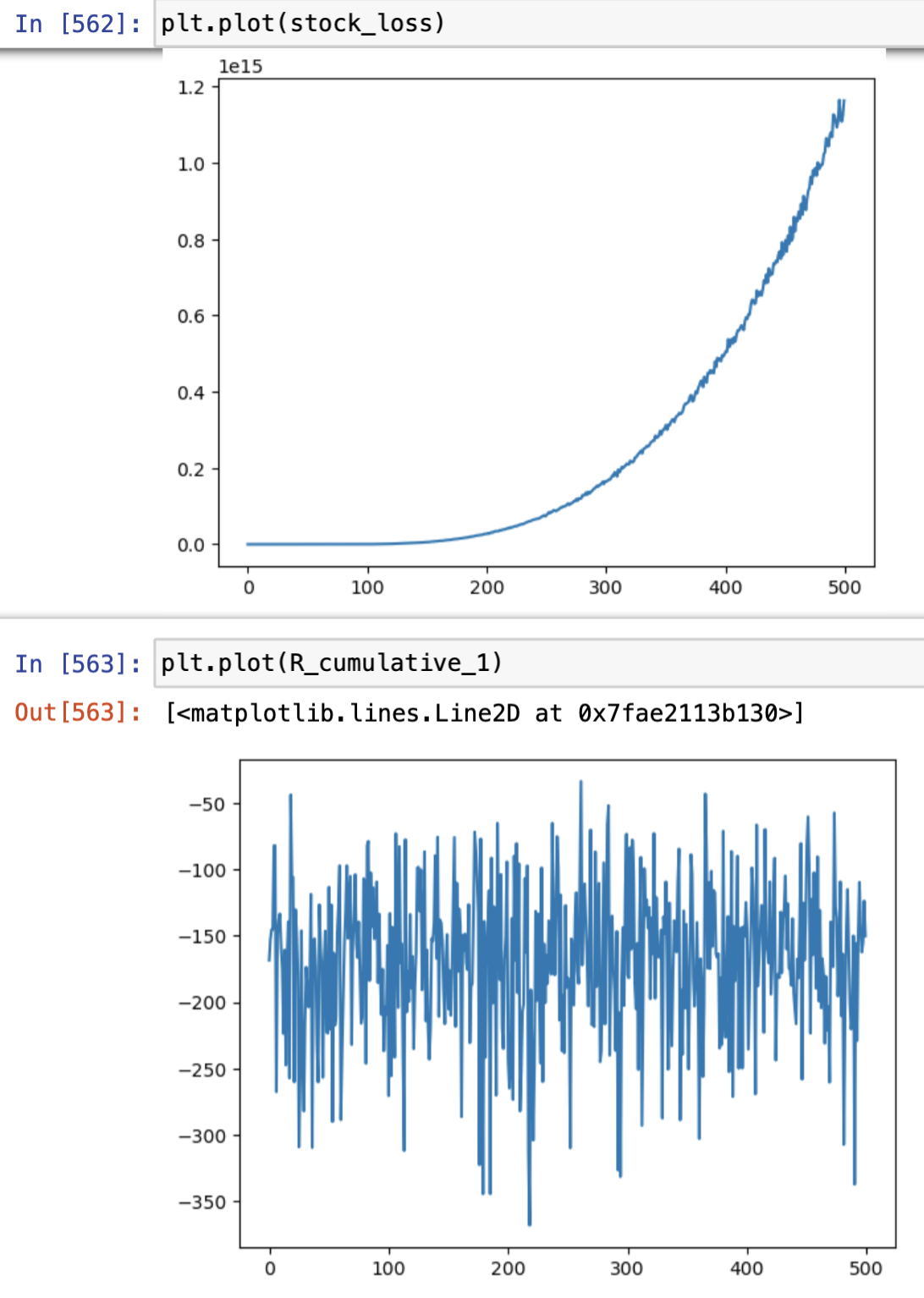
We are still stuck with a network that is not learning. We plotted the cumulative reward (over the 30 weeks) for each episode and the loss over the 500 episodes and see that the loss is increasing too much. We tried with the loss functions F.mse_loss and F.smooth_l1_loss and obtain something similar in both cases. Here are the plots of our cumulative rewards and loss.
Has anyone encountered this problem and managed to fix it? Or could someone please give us some advice on how to solve this problem?
Thanks a lot!